
A journey of reviving something very old
20 years ago, Eksisozluk was founded in 1999 by Sedat (ssg) Kapanoglu. At the time that it was built, it was unique online platform in terms of its format in Turkey. According to the founder, Eksisozluk idea came from “The Hitchhiker’s Guide to the Galaxy” which is written by Douglas Adams. The idea was an online dictionary where the people would contribute by defining any term or word they want to. Eksi sozluk’s (means “Sour dictionary”) motto was “Kutsal bilgi kaynağı” can be translated to “The holy source of the knowledge”. But that declaration actually was a humor. Because the main purpose of Eksisozluk was to having fun and socialize. Every definition of a word or term was called “entry”. Entries did not need to be correct. People could do irony or write incorrect things intentionally to have fun about words or terms if they want to. Entries completely depends on author’s way of thinking about terms and things. The main rule was “whatever you want to write, you have to define the term first, then you can continue to write as you wish.” If we want to give a comparative example, you can think Eksisozluk as mixture of the reddit and the wikipedia but in plain text only. Eksisozluk was gaining popularity over the time since its start.
For its 20th anniversary, I decided to bring back the original Eksi Sozluk to the life to celebrate its 20th b-day. And you will able to experience the early version of Eksisozluk your own. If you want to do this now you can follow this link. But naturally it’s language is in Turkish only. Also I pushed this project’s source code to my github account. So this article will be containing the journey about how I done it.
In February 2015, Eksisozluk founder had published the original source code of Eksisozluk. It was the very early sample of its source code. After couple of months, that source caught my interest. I was very curious about how Eksisozluk was looked at that time because I was a child and naturally I did not know anything about it. I didn’t even have a computer at that time. So I pulled the source from its github repo. The early version of Eksisozluk had written in Delphi to be running as a CGI application. The CGI was quite popular technology to build web applications at those times. Of course the CGI remains very ancient technology today’s standards. But the major Http servers are still supports the CGI applications. Even, they were brought some enhancements to it like Fast-CGI etc. To be able run the source I had to compile it. When I inspect the project file I saw that it was developed with the Delphi 4. I wanted to compile with same version of the Delphi compiler. So I compiled and tried for the first run. I ran it under Apache Http server (httpd) 2.0 and Windows 2000 as the OS. I did it because I wasn’t sure about possible compatibility issues. (Later I tested the compiled executables under Windows 10 and these are worked without any compatibility issue)
It was worked well except a small logic problem in it. I fixed and sent a pull request. So he (ssg) accepted my pull request gracefully. That was my first attempt to work with the original eksi sozluk code.
After 3 years the time was going to a remarkable milestone for Ekşi Sözlük. And I decided to do something for it. I wanted to bring the experience as same as the Eksi Sozluk at that time to the people. This was also “for fun” job for me. So I started this. Before starting this project I set one rule to myself.
Whatever I do, I will not change anything from the original source and the technology that it based on.
Why? Because I want to let people to use early version of Eksisozluk as completely same as its original code and binaries. This project will be run on the same code as of 1999. Yeah that sounds quite fantastic but that brought a lot of things to overcome for me. However, I have to bring some “must have” features to Eksi Sozluk CGI on the fly. Such as pagination support. The original Eksi Sozluk hadn’t any pagination support. Whole topics and entries were placed on the same page. That’s inefficient way to operate today. I have done it without changing any html file for sake of the originality. Let’s begin to meeting the original eksi sozluk’s architecture.
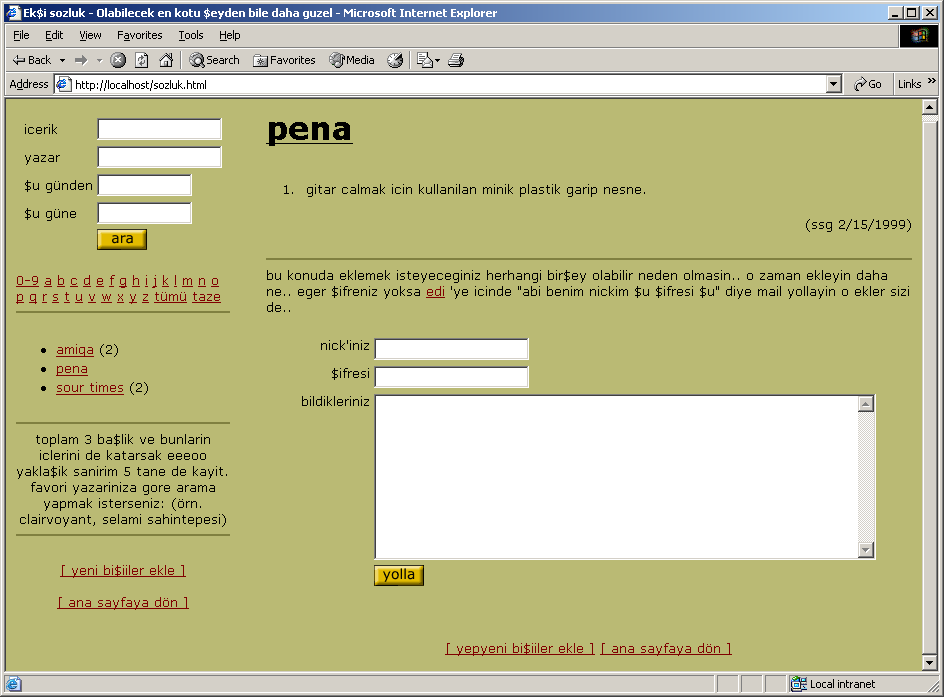
Everything was stored in a text file as plaintext.
Did you surprised? But It was fairly enough to operate the service at the time. Because the early Eksi Sozluk was known by quite limited amount of people. And the most of them, they were friends of each other. These friendships would have came from the real life or from common IRC channels etc. Remaining people were usually friend of those core users. I thought the active registered users were nothing more than 500 at that time. On the other hand, the internet access in turkey at the time was also rare and the internet users weren’t online oftenly. So request and entry addition rates were too low to handle.
The first Eksi sozluk was kept the records in a plain text file like a phone book. Each different type of record was placed in different text file.
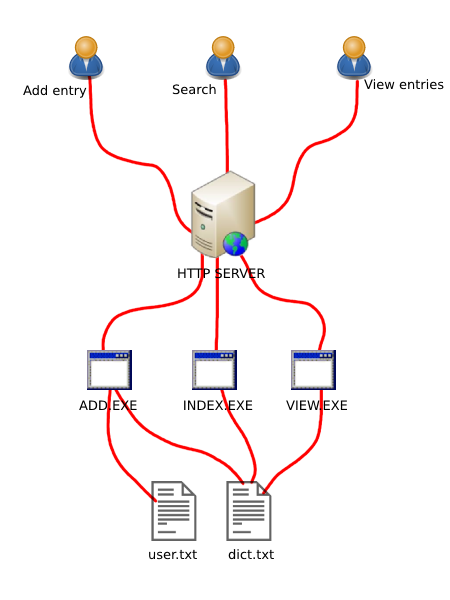
The diagram above shows you the architecture simply. Every user requests were caught by the Http server then passed to the corresponding process. Cgi processes are responsible to handle the raw request.
Eksi sozluk’s logic were separated into several processes to prevent the source become too complex. But it had common core routines (called common.pas) that shared across the processes. Whole records input and output operations were done by sequential file read and write operations. There were two major text files. First is, the dict.txt. Dict.txt was a text file that the entries was stored. Second was user.txt. User.txt was the file for the users information. Fun part about that, the people who were registered earlier, they were experienced faster eksi sozluk than others. Because their user authentication was done quick because of their records were at the beginning of the user.txt :) Of course that delay was in the scale of the milliseconds except user.txt with 10.000 records :P. It would be really pain in the ass if user.txt had thousands of records. The user records made by 3 lines. First line was for user name (Users were called as Suser means “Sozluk User” as far I know), Second was for password in plain text. Yes, but don’t judge. That approach was not too deadly sin at the time. The actual horrible thing is even today, some giant services still store the passwords in plaintext. Anyway, the third line was for e-mail addresses. Every new record (users, entries etc) was marked with ~ (Tilde) character. That would have pointed to the beginning of the new record. Same thing also correct for dict.txt. In perspective for dict.txt, the first line was for baslik (means topic), the second was for Suser nickname, third was for entry addition date, and the fourth was for the entry. The term “entry” was used as is. I don’t know why but there was an inverse situation about the terms. baslik (topic) was used as in Turkish, but the entires were called as “entry” (means “girdi” in Turkish) instead of it’s Turkish form. Probably the word “girdi” was not good to hear. Anyway, you can take a look to the original dict.txt content and it’s structure by clicking here if you want.
Bringing back this ancient system to this day.
The original architecture is obsolete and it’s almost impossible to operate correctly in today’s standards, technology, bandwidth and online internet user capacity. Of course you can still run it for your own with just throwing executables and html files into httpd’s work directories but that’s all. But you have to still be aware to your modern browser’s behavior. If your modern browser send anything that the sozluk-cgi does not love, you may get unwanted results :))
So what I had to do? First I had to eliminate the direct file I/O access to the files then redirect all read write operations to a modern backend. To achieve that, I had to intercept executable’s native File I/O APIs. Sozluk-cgi was used Delphi runtime I/O functions (Internal buffering, caching etc) but eventually they were reach to the Windows file I/O APIs such as (CreateFile, WriteFile, CloseFile etc). After that, these intercepted I/O calls should be analyzed and converted into correct request packets. To do that, I had to study on the Eksi sozluk CGI code. Because to be handle the native I/Os as a request I should know what write read sequences corresponds which type of request or operation. I will be detailed later about this process. After translation of the requests there should be a backend system to handle requests, a database server to be store data efficiently and even a in-memory cache solution to reduce database I/Os. I drew a sketch in my mind about the new architecture for this. And after job done, the system’s structure became this.
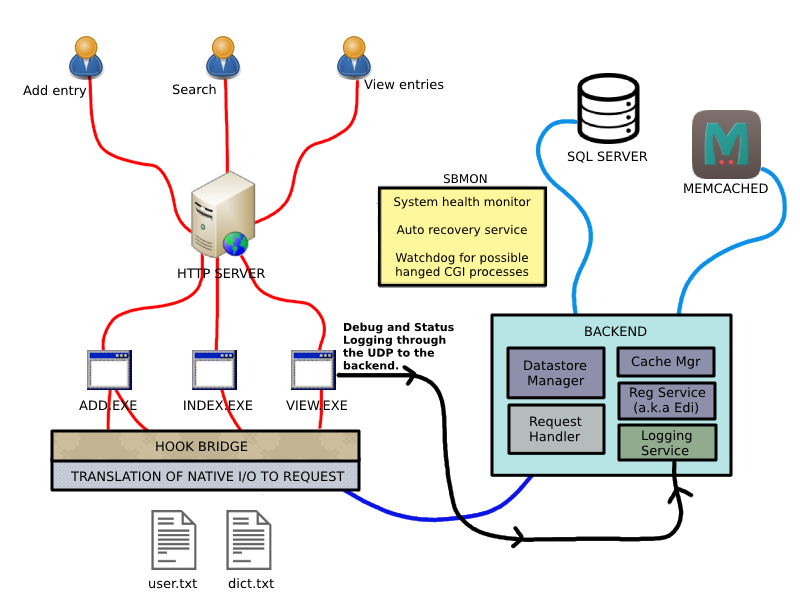
As you can see, there is a hooking layer to make bridge between cgi processes and the backend. The bridge layer is supported by the translation layer which is translates native read write sequences into its simple transportation format. The bridge is a duplex data transfer path which is based on named pipe. Translated request packets are handled by the request handler. The request handler reads the formatted data and maps into corresponding managed work implementation. The datastore manager is responsible to data models I/O. Datastore works with the cache manager internally. It communicates with the SQL Server and the Cache Manager when it need. Cache Manager is a dealer between Memcached instance and the backend. Registration service is responsible for user registration. Do you know why that services also known as Edi? You don’t? Nop. I will tell on its section later. And the Sbmon (Sozluk Backend Monitor) is a tool to monitor system’s health and stability.
Intercepting the CGI Processes
To intercept the native API calls, first I had to inject my bridge and interceptor DLL into the CGI executables. There were a ton of DLL injector tool but I needed a tool that it suitable for my needs. What kind of needs was there?
- Able to work as a command line tool to use it in a batch script
- Able to rebuild OFTs (Original First Thunk)
- Able to accept injection order for Import table
- I don’t like using 3rd party codes or code fragments :) So I can extend quick as I need.
So I wrote a Dll injector tool named “hooker“
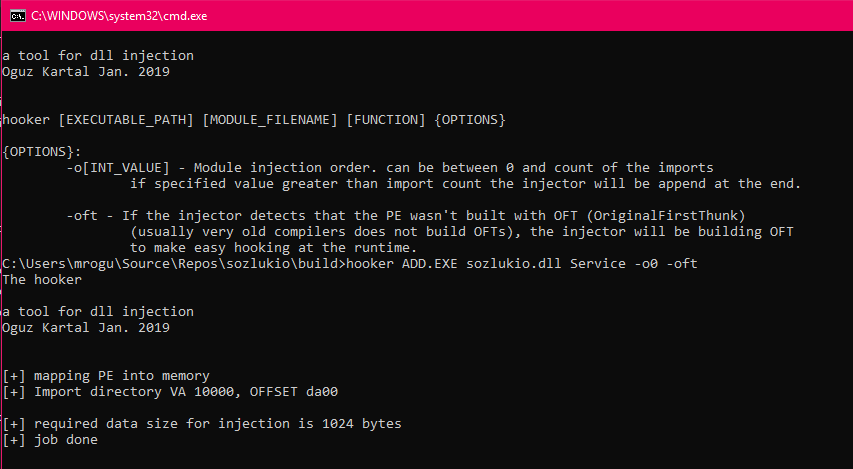
Why I needed to rebuild the OFTs? The answer of this question was laying on the Delphi compiler. The Delphi 4 compiler wasn’t set the Original First Thunk of the IAT (Import address table). Probably, at the time the OFT field was not seen important to set. Yes, that’s not too important info for a PE (Portable Executable, EXE) but that information would made easier our hook progress. Original First Thunk field points to same value as the First Thunk field. Thunk field is a RVA value. That value gives us information about the imported API function. The Operating System’s PE loader reads from the First Thunk to get required API Import information then loads the module into EXE’s address space and puts API’s real address to the First Thunk virtual address. That means you had lost the static import information. Because the OS loader overwrites that memory. If you have Original First Thunk, you can still get the import information otherwise you have to read from the static file. That’s why I want to build OFT
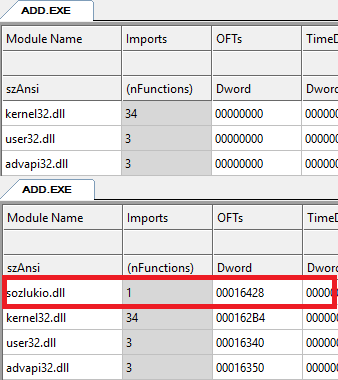
After the injection process, the CGI executables are ready to communicate with the backend. You can see that our bridge & interceptor module (sozlukio.dll) had been injected to the import table with OFT information. And its placed at the beginning of the import table. So the module will be loaded first. sozlukio.dll is native part of the project. It contains the runtime hook routines, native sozluk APIs, I/O translation routines and transport routines.
Let’s take a look initialization of the bridging module. When the sozlukio.dll gets loaded into process’s address space, it tries to connect to the backend. You can see the initialization sequences of the module. The point is if the module could not find a backend to connect, interrupts its job then CGI processes continues its work as its original.
BOOL APIENTRY DllMain( HMODULE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
HkpMyselfModule = hModule;
MtInitialize();
if (!RbConnectBridge())
{
DLOG("There is no backend!!! API hooks disabled.");
return TRUE;
}
HlpInitLogClient();
SetHooks();
HlpGetExecutableName(SioExeName, sizeof(SioExeName));
break;SetHooks routine initializes hook list and calls hook routines for File I/O APIs
BOOL SetHooks()
{
if (!HkInitHook())
return FALSE;
_CreateFileA =
(pfnCreateFileA)HkHookAPI("kernel32.dll", "CreateFileA", (DWORD_PTR)Hook_CreateFileA);
_ReadFile =
(pfnReadFile)HkHookAPI("kernel32.dll", "ReadFile", (DWORD_PTR)Hook_ReadFile);
*
*
*
And so on
return TRUE;
}CreateFileA, WriteFile, ReadFile, CloseHandle, SetFilePointer, GetEnvironmentVariableA are the APIs that needs to be intercepted. After these couple of initialization phases our bridge is completely ready to action. Bridge module just waits the incoming API calls. So how is happening the first action? To understand this we have to take a look the Eksi Sozluk CGI code.
Each CGI executables had a common Initialization procedure. That initialization routines was defined in the Common.pas. The Common.pas had initialization directive to let compiler know the Entry point of the executable like so
initialization
begin
Init;
end;When a executable loaded, the entry point was called the Init routine where defined in the Common.pas. The Init routines looks like this;
procedure Init;
var
si:TStartupInfo;
len:longword;
begin
QueryString := getenv('QUERY_STRING');
if QueryString = '' then begin
len := StrToIntDef(getenv('CONTENT_LENGTH'),0);
if len > 0 then begin
GetStartupInfo(si);
setlength(QueryString,len);
CGIPost := ReadFile(si.hStdInput,QueryString[1],len,len,NIL);
end;
end;
normalizeQueryString(QueryString);
writeln('Content-type: text/html'#13#10);
end;The Init procedure firstly tries to get the Query string value from the Process’s environment variable. The CGI technology puts the query string as a environment variable for GET requests and puts into the Stdin (Standard Input file) for the POST requests. If the routine could not get anything from the environment variable then it goes to the Stdin of the process. To determine if there is any post data, the CGI processes should read CONTENT_LENGTH environment variable. That acts like CONTENT-LENGTH in the HTTP. Like the http, that information indicates the entity body length. If that value greater than zero, that means there is POST data in the stdin. If the CGI process realizes that there is available data to read in the stdin then it gets the stdin handle and calls the ReadFile API using the Stdin handle. As I said before we were hooked the ReadFile API on the Initialization phase of the sozlukio.dll. When the CGI process called the ReadFile API, the execution will be redirected to our Hooked ReadFile function. So we will find a chance to get this data first. Same thing is True for the Environment variable read attempts. We were hooked the GetEnvironmentVariable either. The getenv function actually calls the GetEnvironmentVariable. These calls also falls in our module.
function getenv(s:string):string;
var
ar:array[1..32768] of char;
begin
FillChar(ar,SizeOf(ar),0);
GetEnvironmentVariable(PChar(s),@ar,SizeOf(ar));
Result := Trim(StrPas(@ar));
end;So why I needed to catch these calls? I can read these data without intercept their API calls right? But I had a few reason to do that.
- The pipes are not seekable objects. So if the CGI process read the data before you, you can’t no longer read the data from the pipe. You have read first and cache it then you can send the cached content to the CGI Processes.
- Incoming data needs to be processed before the CGI read. (I will explain why)
- Eksi Sozluk Cgi had few bugs in the Query String parsing / processing routines. (I will talk about these bugs later) To able to escape these bugs I had to apply some workaround process to the data. That’s related with the second bullet.
BOOL WINAPI Hook_ReadFile(
__in HANDLE hFile,
__out LPVOID lpBuffer,
__in DWORD nNumberOfBytesToRead,
__out_opt LPDWORD lpNumberOfBytesRead,
__inout_opt LPOVERLAPPED lpOverlapped
)
{
PFILE_IO_STATE ioState;
BOOL result = FALSE;
if (hFile == GetStdHandle(STD_INPUT_HANDLE))
{
if (!SioHandleReadFileForStdin(lpBuffer, nNumberOfBytesToRead, lpNumberOfBytesRead,lpOverlapped))
goto continueApi;
return TRUE;
}The hooked ReadFile implementation checks if being readed file handle is Stdin handle of the process, if so, it redirects the execution to the special function named SioHandleReadFileForStdin. Otherwise the execution continues through the original implementation.
That function is actually an intermediate function. That actually checks whether the Stdin content had already readed. If it had already readed then it writes cached content to the lpBuffer and sets readed bytes length to the lpNumberOfBytesRead. Otherwise the execution jumps to function named SiopReadStdinPostContent. This function implementation looks like so;
BOOL SiopReadStdinPostContent()
{
BOOL result;
PCHAR temp;
CHAR buf[128] = { 0 };
ULONG realContentLength, readLen;
HANDLE stdinHandle = GetStdHandle(STD_INPUT_HANDLE);
//call original env to read real length
_GetEnvironmentVariableA("CONTENT_LENGTH", buf, sizeof(buf));
realContentLength = strtoul(buf, NULL, 10);
*
*
*
SioCachedPostContentLen = realContentLength;
result = _ReadFile(stdinHandle, SioCachedPostContent, realContentLength, &readLen, NULL);
if (result)
{
readLen = HlpReEncodeAsAscii(
SioCachedPostContent,
SioCachedPostContentLen,
&temp,
SiopCleanUnwantedCharsFromTheBaslik
);
if (SioCachedPostContent != temp)
{
HlpFree(SioCachedPostContent);
SioCachedPostContent = temp;
}
SioCachedPostContentLen = readLen;
}
*
*
*
return result;
}The function that it showed above, gets the available data length from the environment variable using the original API call then reads entire content from the pipe. The highlighted line is a tricky part of that routine. The HlpReEncodeAsAscii function re-encodes the POST content into the ASCII. The Sozluk CGI works with only ASCII encoded content. But the users may send non-ASCII content that includes the Turkish accent characters which are defined in ISO 8859-9. And naturally Sozluk CGI can’t handle correctly these encoded content. Before pass them back to CGI Process, the interceptor module converts the data. For example if an user attempts to send a word like “doğrulanmamış”, the module converts into “dogrulanmamis” which is its decomposed form.
Bugs bugs bugs…
So what’s the tricky part is? Actually the HlpReEncodeAsAscii does more than character encoding translation. Today’s modern browsers may send html entity contained data to the http server. So the Sozluk CGI can’t handle these as well. Sozluk CGI decodes simply the percentage encoded data. Let’s take look closer to the Sozluk CGI’s decoding logic. Sozluk CGI had a decoding procedure named “normalizeQueryString” like so;
procedure normalizeQueryString(var s:string);
var
n:integer;
b:integer;
begin
repeat
n := pos('%',s);
if n = 0 then break;
if HexToInt(copy(s,n+1,2),b) then begin
Delete(s,n,3);
Insert(char(b),s,n);
end else s[n] := #255;
until false;
s := Replace(s,'<','<');
s := Replace(s,'>','>');
s := Translate(LowerCase(Trim(s)),'+'#255,' %');
end;First it unescapes the percentage encoded data. The key point is that it scans from the beginning in every iteration to catch the ‘%’ characters after the previous unescape iteration. For example the %253C becomes to the %3C after the unescape which is encoded form of the ‘<‘ (less than) character. So that prevents possible html injection attacks like XSS. That was a good idea but quite inefficient way to do. But I hadn’t let that happen :) I tell you why. Give your attention to 15th and 16th lines of the procedure. You should see a few function call named Replace. The Replace was a helper function which is finds a sequences within a string and replaces with a given another string. That was defined in Common.pas. But it has a major bug. Let’s take a look it’s implementation.
function Replace(s,src,dst:string):string;
var
b:byte;
begin
repeat
b := pos(src,s);
if b > 0 then begin
Delete(s,b,length(src));
if dst <> '' then Insert(dst,s,b);
end;
until b = 0;
Result := s;
end;The variable named ‘b’ was used to hold position of the string that had been found. But the main problem is it’s variable type. It was declared as the byte type. And the byte datatype can be hold values between 0 – 255. But the Pos returns a value for the type of Integer. If the Pos function returns a position value greater than 255 the variable ‘b’ gets overflowed and as a result the content would be corrupted either. So I had two issue to fix.
- I would have to escape the % characters in the plain text data. For example if someone send malicious %3C or %3E as plain input data, the browser would be encode these as %253C or %253E. So the normalizeQueryString procedure eventually decodes into the < and > characters. And these are would made the Replace function worked wrong.
- Users would send non-malicious < or > characters within the entry content. These data also could trigger the Replace procedure bug.
I had to replace these chars with anything else to keep away from the bug. I decided to replace these chars with a format like the html entity. Actually I wanted to convert these as html entity form but I had hit to another bug :)
DWORD HlpUrlEncodeAscii(PCHAR value, ULONG length, PCHAR *encodedValue, BOOL includeReserved)
{
PISO_8859_9_TR_CHARS encTable;
DWORD encLen = 0;
PCHAR pEnc,p;
ULONG pEncSize = ((length + 5) * 3) + 1;
*
*
*
for (INT i = 0; i < length; i++)
{
//Workarounds
if (value[i] == '<' || value[i] == '>')
{
sprintf(pEnc + encLen, "$%s;", value[i] == '<' ? "lt" : "gt");
encLen += 4;
continue;
}
else if (value[i] == '&')
{
strcpy(pEnc + encLen, "$amp;");
encLen += 5;
continue;
}
else if (value[i] == '=')
{
strcpy(pEnc + encLen, "$eq;");
encLen += 4;
continue;
}
else if (value[i] == '%')
{
strcpy(pEnc + encLen, "$percnt;");
encLen += 8;
continue;
}The HlpUrlEncodeAscii replaces these problematic characters to theirs equivalent before the encode process. The ‘<‘ becomes the ‘$lt;’, The ‘>’ becomes the ‘$gt;’ and the ‘%’ becomes the ‘$percnt;’. But you have probably seen the same thing done for some others. That was related with another bug that I hit during the development. So the problematic characters passed through the normalizeQueryString procedure using this workaround. Ok but Why this workaround had applied for the & (ampersand) and = (equals sign) also? Before answering this question, I want to talk about last thing with the normalizeQueryString procedure.
The normalizeQueryString translates the + plus characters into the spaces as it’s final job. This causes you to lost the + character from the user supplied content. If users would want to write something like “hey 1 + 1 is not 2”, it would be converted into the “hey 1 1 is not 2” which is meaningless sentence. Sozluk CGI should have done this before the decoding process. Because the + (plus) character could be encoded as the %2B. After the decoding process the + plus characters are no more count as the URI special character. That was the another thing that I had to fix.
I had to avoid from the & (Ampersand) and the = (equals sign) because the sozluk-cgi’s querystring parser was also problematic.
The getValue was a function to read a parameter value from the querystring. But the main problem is that it hadn’t respected the URI scheme. getValue function was working on the decoded data.
sub := getParse(QueryString,'&',n);
if LowerCase(GetParse(sub,'=',1)) = s then begin
Result := GetParse(sub,'=',2);
exit;
end;getValue calls the getParse function to split the querystring into key value parts to read the parameter and it’s value. But remember that the querystring becomes the unescaped plaintext after the decoding process. If the users or browser send a content that contained the ‘&’ or ‘=’ chars, the getParse would easily returns unexpected result. Because the getParse wasn’t doing anything special for the URI scheme. That’s why I avoided from these.
Let’s imagine that someone wants to send this content.
(1 & 1) || (2 > 1) %253Cx%253E
They are all bug trigger and malicious content for the Sozluk CGI. But it will be telling you how the workaround made the transport safe such a junk data to the backend.
When this content send, the browser would encode the content like so;
%281+%26+1%29+%7C%7C+%282+%3E+1%29+%25253Cx%25253
Of course this is not human readable. This is standard percentage encoding procedure. Then the browser would push the data to the server. When the CGI Process attempt to read those data, our module arrives as a middle man and re-encodes the data like so;
%281%20$amp;%201%29%20%7c%7c%20%282%20$gt;%201%29%20$percnt;253Cx$percnt;253E
The bold marked parts are workaround for our re-encoding process. So the sozluk cgi won’t be in trouble with that. Those data passes through the normalizeQueryString, getValue or the getParse with no problem. There are no bugs and no issues anymore.
Those data would arrive to the backend without a problem. So the backend decodes the data as;
(1 $amp; 1) || (2 $gt; 1) $percnt;253Cx$percnt;253
These are almost done. But the backend have to unescape our non-standard entites from it. The backend’s special function translates these as it’s expected form. So the data becomes this;
(1 & 1) || (2 > 1) %253Cx%253E
Great! Finally I can get the data without corruption. But this data still malicious to put into the database. :) The backend calls a special function named “SanitizeForXSS“. After that the content becomes fully safe to show to the users.
After these workarounds, I realized that this version of the sozluk-cgi I worked on, is not the final version. I would say this was beta
The User (Suser) Authentication
The susers had to authenticate theirs identity to be able to add entry. So the sozluk cgi would have scan through the user.txt to find suser’s record. Then it was doing comparison for the nick and the password fields. If it was matched with the supplied info then the sozluk-cgi can be passed to the entry addition sequence. The GetUserPass function was responsible to find the user record and return its password in plaintext.
normalizeword(word);
realpass := GetUserPass(nick);
if (desc='') or (nick='') or (word='') or (realpass='') or (realpass <> password) then begin
msg := 'OLMAZ SENiN i$iN!'
end Let’s take a look it’s implementation.
function GetUserPass;
var
F:TextFile;
s:string;
begin
AssignFile(F,userFile);
Reset(F);
if IOResult = 0 then while not Eof(F) do begin
Readln(F,s);
if s <> '' then if s[1] = '~' then begin
if Trim(copy(s,2,length(s))) = username then begin
Readln(F,s);
Result := Trim(s);
CloseFile(F);
exit;
end;
end;
end;
CloseFile(F);
Result := '';
end;I won’t describe every line one by one. That is quite clear. But the highlighted line had brought an issue to handle it again. The GetUserPass was taking an argument for the password that supplied by the user. Yes I could hook the entire file I/O APIs but how would I know the username to be matched? If I know that info I would trick off the CGI. But even the CGI process gets this info from the querystring right? I could do the same thing. Let’s see what I have done.
BOOL WINAPI Hook_ReadFile(
__in HANDLE hFile,
__out LPVOID lpBuffer,
__in DWORD nNumberOfBytesToRead,
__out_opt LPDWORD lpNumberOfBytesRead,
__inout_opt LPOVERLAPPED lpOverlapped
)
{
PFILE_IO_STATE ioState;
BOOL result = FALSE;
*
*
*
ioState = SioGetIoStateByHandle(hFile);
if (ioState)
{
switch (ioState->type)
{
*
*
case UserTxt:
result = SioHandleReadFileForUser(ioState,lpBuffer,nNumberOfBytesToRead,lpNumberOfBytesRead);
break;
*
*
continueApi:
return _ReadFile(hFile, lpBuffer, nNumberOfBytesToRead, lpNumberOfBytesRead, lpOverlapped);
}If the ReadFile hook function detected the file to be read is a user.txt, then it redirects the execution to the SioHandleReadFileForUser. Here is the related part of this function.
BOOL SioHandleReadFileForUser(PFILE_IO_STATE state, LPVOID buf, DWORD readSize, DWORD *readedSize)
{
BOOL result = FALSE;
PCHAR psz;
CHAR nick[64] = { 0 };
CHAR password[64] = { 0 };
ULONG ulen = 0, plen = 0;
DWORD readLen = 0;
if (state->FilePointer.low == 0)
{
if (state->exeName == VIEW)
{
SiopDeliverFakeSuserDataForExistenceCheck(state, buf, readSize, readedSize);
return TRUE;
}
ulen = SioGetRequestValue("nick", nick, sizeof(nick));
plen = SioGetRequestValue("password", password, sizeof(password));
if (ulen > 0 && plen > 0)
{
ulen = HlpUrlDecodeAsAscii(nick, ulen);
plen = HlpUrlDecodeAsAscii(password, plen);
CharLowerA(nick);
CharLowerA(password);
//this is authentication for entry addition process
if (!SzAuthSuser(nick, password))
{
if (readedSize)
*readedSize = 0;
//Auth failed. just send eof to the cgi program
//so the cgi handler also will be failed.
SIOLOG("Auth failed for %s", nick);
return TRUE;
}
psz = (PCHAR)buf;
*psz = '~'; //set nickname mark first
readLen = 1;
strcpy(psz + readLen, nick);
readLen += ulen;
strcpy(psz + readLen, "\r\n");
readLen += 2;
strcpy(psz + readLen, password);
readLen += plen;
strcpy(psz + readLen, "\r\n");
readLen += 2;
*readedSize = readLen;
state->FilePointer.low += readLen;
SIOLOG("nickname and pwd passed to the backend (%s)",nick);
result = TRUE;
}
else
{
*readedSize = 0;
result = TRUE;
}
}
else
{
if (state->exeName == VIEW)
{
SiopDeliverFakeSuserDataForExistenceCheck(state, buf, readSize, readedSize);
return TRUE;
}
*readedSize = 0;
result = TRUE;
}
return result;
}This function gets the required parameters such as “nick” and the “password” then pass them to the sozluk native api named SzAuthSuser. If it successful, then puts the nickname and the password as it’s sequential record format. Puts the new record mark ~ (Tilde) first, then the nickname and so on. So the CGI Process successfully tricked off. the CGI process will be thinking that the record have been found in the first shot :)
The sozluk cgi wants the password as plain text. But for security reasons I should haven’t store the passwords as plain text. That was not a big problem. Actually it was not a problem. As you can see above if the authentication successful, I passing back the password that it given by the user as a input to the CGI process. But in the perspective of the backend the passwords are stored in the SQL Server as salted and hashed with the SHA-512.
public static string SecurePassword(string pass)
{
return Helper.Sha512(SALT1 + FixPassword(pass) + SALT2);
}If the authentication process gets fail, the function returns a status for “there is no kind of record you lookin for” through the ReadFile API.
The Entry Addition
After the authentication, the sozluk cgi can be add the entry content to the dict.txt, actually to the database for now. Sozluk CGI simply opens the dict.txt and writes the entry data to the end of the file. Like so;
T := TFileStream.Create(dictFile,fmOpenWrite);
T.Position := T.Size;
msg := '~'+word + #13#10 + nick + #13#10 + DateToStr(Now)+' '+getenv('REMOTE_ADDR') + #13#10 +
desc + #13#10;
T.Write(msg[1],System.length(msg));
T.Free;
msg := 'EKLEDiM!';
CloseFile(F);Any attempt to open a file will be caught by our hook. So
HANDLE WINAPI Hook_CreateFileA(
__in LPCSTR lpFileName,
__in DWORD dwDesiredAccess,
__in DWORD dwShareMode,
__in_opt LPSECURITY_ATTRIBUTES lpSecurityAttributes,
__in DWORD dwCreationDisposition,
__in DWORD dwFlagsAndAttributes,
__in_opt HANDLE hTemplateFile
)
{
*
*
RcReadRequest(&SioRequest);
*
*
*
if (fileIoHandle->type == DictTxt)
{
if (fileIoHandle->exeName == INDEX)
{
SioHandleCreateFileForIndexAndSearch(fileIoHandle);
}
else if (fileIoHandle->exeName == ADD)
{
fileIoHandle->tag = SiopCreateWriteBuffer(256);
}
}
*
*
*
}If the file to be read is the dict.txt and the executable is ADD.EXE, our module creates a write buffer and attaches to it’s Io Object. So following WriteFile calls would get the write buffer from the Io Object. The WriteFile hook simply writes the incoming data to the write buffer which is auto expandable.
When the all write operations completed, the CGI process eventually calls the CloseHandle API to flush and the close the file. CloseHandle hook calls the entry addition routine with it’s Io Object. That’s not a direct call for sozluk native API. It calls an intermediate routine to prepare entry context.
BOOL SioAddNewEntry(PFILE_IO_STATE state)
{
PFILE_WRITE_BUFFER pWrBuffer;
BOOL result;
DWORD written = 0;
SOZLUK_ENTRY_CONTEXT sec;
memset(&sec, 0, sizeof(sec));
pWrBuffer = (PFILE_WRITE_BUFFER)state->tag;
if (!pWrBuffer)
{
SIOLOG("invalid fwb !");
return FALSE;
}
SIOLOG("Building entry context from IO Buffer");
if (!HlpBuildEntryContextFromWriteData((PAUTO_BUFFER)pWrBuffer, &sec))
return FALSE;
SIOLOG("new entry for %s (%s)", sec.Baslik, sec.Suser);
if (!SzAddEntry(&sec))
{
result = FALSE;
goto oneWay;
}
result = TRUE;
SioGetIoStateByFileType(AddTxt)->status |= FIOS_KEEP_TAG;
SioGetIoStateByFileType(AddTxt)->tag = (LPVOID)sec.BaslikId;
oneWay:
HlpFree(sec.Desc);
return result;
}This function does some preparation for the entry addition process. It gets the write buffer object which is attached to the Io Object. The HlpBuildEntryContextFromWriteData builds the entry context from the natively written data. I had to build structured entry context to pass them to the backend properly.
The highlighted lines shown above is for the redirection progress. A status page welcomes you after you have added an entry. It waits a bit and redirects you to the topic again. Like so

If the baslik’s total entry count greater than the entry count per a page and the user was staying at the page other than the last one, the redirection should be go to the latest page. This message was building using a template file named add.txt. Add.txt contains this to make http redirection
<meta http-equiv="refresh" content="2;URL=/cgi-bin/view.exe?%queryword">the “%queryword” was like a format identifier. The CGI process would have replace it with a topic name. Of course the view page would be redirected to that topic. SioAddNewEntry sets the topic’s id to the Add.txt’s Io Object’s tag.
baslikId = (ULONG)fileIoHandle->tag;
fileIoHandle->status &= ~FIOS_KEEP_TAG;
fileIoHandle->tag = iobuf;
index = HlpStrPos((PCHAR)iobuf->buffer, "%queryword");
if (index >= 0)
{
iobuf->pos = HlpRemoveString((PCHAR)iobuf->buffer, iobuf->pos, "%queryword");
slen = SioGetRequestValue("word", buf, sizeof(buf));
HlpInsertIntoAutoBuffer(iobuf, index, buf, slen,0);
index += slen;
slen = sprintf(buf, "&bid=%lu&latest=1", baslikId);
HlpInsertIntoAutoBuffer(iobuf, index, buf,slen,0);
}Bridge module intercepts the template file’s (Add.Txt) I/O and inserts a few additional parameters. When the backend see the “latest” parameter is set, then it loads the last page. So the users could see theirs entries as a fresh content.
Entry view and the pagination support as a new feature
Sozluk CGI was using very primitive template system to build its content. The view section was one of them. Show.txt was the template file to build entry view. Sozluk CGI would have scan entire dict.txt to get entries of a topic (baslik) then it generates the html content using the template items. Sozluk CGI loads the show.txt into the memory, then the view content can be build. I had to intercept also the show.txt’s content to inject some additional html fragments. One of these fragments is the pagination html data. As you guess I had to fetch the entries during the Show.Txt’s read event. Because I had to know some information like how many entries and pages are there.
HANDLE WINAPI Hook_CreateFileA(
__in LPCSTR lpFileName,
__in DWORD dwDesiredAccess,
__in DWORD dwShareMode,
__in_opt LPSECURITY_ATTRIBUTES lpSecurityAttributes,
__in DWORD dwCreationDisposition,
__in DWORD dwFlagsAndAttributes,
__in_opt HANDLE hTemplateFile
)
{
HANDLE handle;
PFILE_IO_STATE fileIoHandle = NULL;
PAUTO_BUFFER iobuf;
BOOL createOriginalFile = FALSE;
CHAR buf[256];
CHAR fileName[MAX_PATH] = { 0 };
RcReadRequest(&SioRequest);
HlpGetFileNameFromPath((PCHAR)lpFileName, fileName, sizeof(fileName));
*
*
*
else if (fileIoHandle->type == ShowTxt)
{
PFILE_IO_STATE dictIo;
PENTRY_VIEW_QUERY_RESULT entryListCtx;
dictIo = SiopReserveIoState(DictTxt);
iobuf = HlpCreateAutoBuffer(GetFileSize(fileIoHandle->realHandle, NULL) + 1);
fileIoHandle->tag = iobuf;
_ReadFile(fileIoHandle->realHandle, iobuf->buffer, iobuf->size, &iobuf->pos, NULL);
SiopReplaceEdiContactInfo(iobuf);
if (SioHandleCreateFileForViewEntry(dictIo))
{
entryListCtx = (PENTRY_VIEW_QUERY_RESULT)dictIo->tag;
SiopBuildSuserListForExistenceCheck(entryListCtx);
SiopSetEntryWordbreakStyle(iobuf);
SiopBuildViewPaginationHtml(
iobuf,
entryListCtx->RecordsPerPage,
entryListCtx->TotalPageCount,
entryListCtx->CurrentPageNumber,
entryListCtx->Baslik,
entryListCtx->BaslikId
);
}
}
fileIoHandle->fakeHandle = fileIoHandle;
fileIoHandle->FilePointer.low = 0;
fileIoHandle->FilePointer.high = 0;
//return fake handle
return fileIoHandle;
}The SioHandleCreateFileForViewEntry fetches the entries using the information like topic name, id, page number etc. from the backend. The result attaches to the Dict.txt’s Io object, not for Show.txt. Show.txt needs the query result just for build the pagination enabled template content. The result actually needed in the Dict.txt’s read event. So I would have to keep it until the Dict.txt gets opened. The SiopSetEntryWordbreakStyle sets the word-wrap attribute of the “p” element to “break-word” on the fly. That makes the entries no more floats out of the viewport.
The SiopBuildViewPaginationHtml is responsible for build pagination html data.
The remaining things are about the translation of the entry context to the native format and dispatching them to the CGI processes. I don’t need to detail them. You can get the source code of this project from my github page.
The Search and the Index section on the Left frame
The left frame’s build logic (Listing, Paging etc) is almost as same as the View section. So I will describe it’s differences only. If you take a look to the left frame, you would see the topics names and the numerical information that indicates to how many entries there are in the topic. Sozluk CGI was doing sequential I/O. It was getting the record lines one by one and incrementing the entry count if anything matched with the given criteria. I should have to do same thing within the SQL. Sozluk CGI search facility was doing following things for the texts.
- The content field looks for the description and the topic (baslik) name fields. If the search criteria can’t be matched for the any entry of the topic but can be matched for the topic name, it counts as a found record.
- String match operation is doing by looking for the being searched text is in the other one or not. Because of that, sadly I had to eliminate using the Full text search for this. So I should have brought the original experience.
First I wrote a few base SQL query for each type of query such as the search or indexed topics. So the SQL module would derive more special forms from these. For example if an user wants to search the term “cach” the SQL query will generated like this;
SELECT * FROM (
SELECT
ROW_NUMBER() OVER(Order By Baslik) as RowNum,
Baslik,
COUNT( CASE WHEN Baslik LIKE '%cach%' AND Descr NOT LIKE '%cach%' THEN NULL ELSE Baslik END ) As EntryCount,
COUNT(*) OVER() As TotalRecordCount
FROM (
SELECT
Entries.Id,
Basliks.Baslik,
Susers.Suser,
Entries.Descr,
Entries.Date
FROM Basliks
INNER JOIN Entries ON Basliks.Id = Entries.BaslikId
INNER JOIN Susers ON Susers.Id = Entries.SuserId
WHERE (Basliks.Baslik LIKE '%cach%' OR Entries.Descr LIKE '%cach%')) ConditionSubQuery GROUP BY Baslik )
FilterQuery
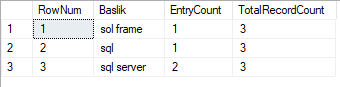
WHERE RowNum BETWEEN 1 AND 15;This query gives us this;

The term “cach” was existing for 2 times in the baslik called “memcached”. The query was counting just for the entries that are contained the “cach”. If I execute for the term “eksi”, the result would be like this;

The entry count was zero because there was no entry that was containing the term “eksi” but the query was still counting the “eksi sozluk” as a record. Because it’s topic’s name was containing the “eksi”. The TotalRecordCount is holds total number of the record that match. For example when you click the index selector “s” which is located in the left frame, the result would be like this;
In this type of requests the query yields the total entry count of the topic.
Ok I could get results as I want. But I would have to serve that result as expected by the sozluk cgi. And to do that I would have to send these as the sequential data format. And it should have done as repetitively.
So I had put a field to the entry record to hold repetition count.
public string GetTransportString()
{
StringBuilder sb = new StringBuilder();
string s;
if (RepCount > 1)
sb.Append(MakeTag("Baslik", this.Baslik, "RepCount", RepCount));
else
sb.Append(MakeTag("Baslik", this.Baslik));
sb.Append(MakeTag("Suser", Suser));
sb.Append(MakeTag("Date", Date));
sb.Append(MakeTag("Desc", Content));
s = sb.ToString();
sb.Clear();
sb = null;
}
The repetition value actually is the record count. The backend sets the value as an attribute if the record count more than one.
When those data arrives to our interceptor module it handles it like so.
DWORD SiopDeliverEntryContent
(
PSOZLUK_ENTRY_CONTEXT entries,
DWORD *pIndex,
LONG recordCount,
DWORD state,
PCHAR buf,
DWORD readSize,
DWORD *readedSize
)
{
PSOZLUK_ENTRY_CONTEXT entry;
DWORD index = *pIndex;
DWORD written = 0, totalWritten = 0;
for (int i = index; i < recordCount; i++)
{
entry = &entries[index];
SiopPrepareEntryForReadSequence(entry);
state = SiopFillReadBufferWithEntry(buf, readSize, entry, state, &written);
totalWritten += written;
buf += written;
readSize -= written;
if (state & ERS_PARTIALCHECK_MASK)
{
//Hmm there is remained part which is caused by lack of buffer size.
break;
}
if (entry->RepCount > 0)
{
entry->RepCount--;
if (entry->RepCount == 0)
{
index++;
}
}
else
index++;
}
*pIndex = index;
*readedSize = totalWritten;
return state;
}The SiopDeliverEntryContent is responsible for converting entries or topics to the sozluk-cgi’s native plaintext format and sending to the CGI process. If there is repetitive content to deliver, it continues to send them same record content through the ReadFile API until repcount becomes zero. Then it can be pass to the next record.
The datetime issue on the Search
The sozluk-cgi had a logic problem with it’s date range check. the sozluk cgi was skipping even if the submit date of an entry is in the search date range.
if hasdate then if (date >= fd) and (date <= td) then continue;fd is for from date which is lower bound of the range, and td is for to day which is the higher bound. if the submit date of the entry is between them it skips the record. To reverse this behavior, I had to push the date out of the search date range. So
//Workarounds, workarounds, workarounds !
if (begin != DateTime.MinValue && end != DateTime.MinValue)
{
if (leaveDatesAsIs)
{
deceptedDate = begin.AddTicks((end - begin).Ticks / 2).ToString();
}
else
{
//push it out of from the search date range to reverse daterange check logic
deceptedDate = end.AddDays(2).ToString();
}
}
else
deceptedDate = string.EmptyThat was ugly, but necessary :
A few small features
- Multi empty line feed support. Sozluk cgi was supporting one crlf per line.
- Keeping entry number reference on different pages.

The User registration
The user registrations were done directly by a person. Sozluk CGI had a user addition code but that was not usable. So I had to implement my own registration system. That registration system called “Edi” runs under the backend. But the edi is a standalone Http server to execute the registration logic. It runs at the port number 1999. The name of “Edi” is a reference to the registration instruction that stays at the entry addition form.

It was saying “if you don’t have a password, send an e-mail to edi, that contains “hey brother, that’s my nickname and that’s the password of it” so he adds you too.
I’m not sure but probably Edi was a person who responsible such a job :) That Why I call this Edi.
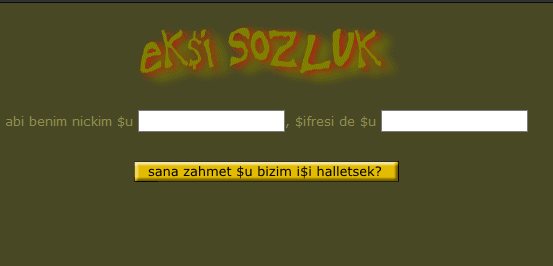
This page is not part of the original source. I had done it using the sozluk’s original materials except the button.
The Caching
The backend uses the memcached as a in-memory caching solution to reduce SQL server number of the execution. Every resultset of a query cached into memcached instance through the Cache Manager. And each type of record has different cache invalidation timeout. Or some of them can be invalidated when needed.
The Health Monitor (SBMON)
Sbmon (Sozluk Backend Monitor) is tool that I wrote to monitoring the system’s health including CGI processes, Memcached instance, and the backend service. That also able to recover if any component of the system gets hang or gets crash. The watchdog is responsible for monitoring possible hanged CGI processes. If it detects any being hanged process, it kills them all.
Sbmon has few recover policies. So recovering process depends on the policies
The Logging
The backend has a logging service for itself and other components. Other components (the intercepted CGI processes) sends the log data through the UDP to the backend. The backend writes those logs into a categorized log file.
The Config
The backend pulls the configuration parameters from the “.config” file. The configuration file looks like so;
memcached_port = 2552
memcached_path = c:\sozluk\memcached.exe
sbmon_path = c:\sozluk\backend\sbmon.exe
log_level=6
dbpwd=PASSWORD
test_mode= True
html_asset_root=c:\sozluk\htdocs
cacheset_salt=29&93*fk2&22++1
records_per_page=10
basliks_per_page=15Quite clear. These configuration parameters are describes their purpose. The .config should be in the same directory of the backend executable. If one of required parameters is missing or wrong, the system does not start.
Those information are just shared to letting you know about them. So I don’t expect anyone to try to build and execute this project.
The Boot.exe
The Boot.exe is responsible to booting up entire system from scratch. I had written this tool to startup the system quickly during the development phase.
Final Words
Probably I had forgotten to tell many thing about this. But I thought I told the key things about what I have done it. Eksi Sozluk is one of the most visited online web service today. And I believed this project was worthy to dedicate to one of the most important work in every aspect. This project had taken about a month. Maybe plus a few days additionally. But I was having a lot fun while working on this project. Because this was kinda puzzle game for me. So the funny things are done at the celebrations. And this is my way to celebrate.
Hocam bu dünyada kimsenin bu kadar boş vakti olmamalı ya, saygılar çok güzel yazı olmuş.
teşekkürler. boş vaktim aslında zannettiğin kadar değildi :) projenin büyük kısmını kendi kişisel zamanımdan ayırıp yapmıştım.
hmm
Issiz desen… o da degil. Emege saygi +rep
Yani ne denir ki, valla bravo
Sıkılmadan okudum, muhteşem!
Tebrik ederim hocam müthiş bir çalışma.
mükemmel bir çalışma.
For anyone who hopes to find valuable information on that topic, right here is the perfect blog I would highly recommend. Feel free to visit my site Webemail24 for additional resources about Replicas.
Hey there, I appreciate you posting great content covering that topic with full attention to details and providing updated data. I believe it is my turn to give back, check out my website Seoranko for additional resources about SEO.
For anyone who hopes to find valuable information on that topic, right here is the perfect blog I would highly recommend. Feel free to visit my site ArticleHome for additional resources about Blogging.
Superb layout and design, but most of all, concise and helpful information. Great job, site admin. Take a look at my website Autoprofi for some cool facts about Auto Export.
Informative articles, excellent work site admin! If you’d like more information about Bitcoin, drop by my site at Articlecity Cheers to creating useful content on the web!
As someone still navigating this field, I find your posts really helpful. My site is Articleworld and I’d be happy to have some experts about Bitcoin like you check it and provide some feedback.
I like the comprehensive information you provide in your blog. The topic is kinda complex but I’d have to say you nailed it! Look into my page Article Sphere for content about Classified Ads.
This was a delight to read. You show an impressive grasp on this subject! I specialize about Cosmetics and you can see my posts here at my blog 71N Keep up the incredible work!
My site UY5 covers a lot of topics about Airport Transfer and I thought we could greatly benefit from each other. Awesome posts by the way!
Nice post! You have written useful and practical information. Take a look at my web blog FQ4 I’m sure you’ll find supplementry information about Cosmetics you can gain new insights from.
An excellent read that will keep readers – particularly me – coming back for more! Also, I’d genuinely appreciate if you check my website 46N about Cosmetics. Thank you and best of luck!
Amazing Content! If you need some details about about Cosmetic Treatment than have a look here UQ8
The way you put together the information on your posts is commendable. I would highly recommend this site. You might also want to check my page UQ4 for some noteworthy inputs about Cosmetics.
2026 yılından merhaba. vay be. ne emek.